GraphView is a middleware of database.
A graph is a structure that's composed of vertices and edges. Both vertices and edges can have an arbitrary number of properties. Vertices denote discrete objects such as a person, a place, or an event. Edges denote relationships between vertices.
GraphView could let you store, manipulate, and retrieve a graph on relational database or NoSQL database by SQL-like language or Gremlin language.
We implement GraphView in C#, which is an open source project published on Github.
We divide a Gremlin query into three parts, including translation, compilation, execution. And if SQL-like language is used, the latter two parts will enough.
Semantics always come first. They define the problem.
GraphView needs Microsoft.SqlServer.TransactSql.ScriptDom.dll. Download and install SQL Server Data Tools.
- Visual Studio, programming languages -> Visual C# -> Common Tools for Visual C#
- Install SQL Server Data Tools
- Clone the source code: git clone https://github.com/Microsoft/GraphView.git
- Open GraphView.csproj
- Set the configuration to "release"
- Build the project and generate GraphView.dll
GraphView provide two ways to store, manipulate and retrieve a graph. One way is to use C# API, the other is to use a string variable to maintain the command. If we use the latter way, GraphView will replace the gremlin-groovy statement with the C# codes by regular expressions and generate a complete C# codes. And then compile and execute them in GraphView runtime dynamicly. So it is more vital to understand the former way.
Let's start from an easy example.
GraphViewCommand command = new GraphViewCommand(graphConnection);
var traversal = command.g().V().Has("name").Out("created");
var result = traversal.Next();
foreach (var r in result)
{
Console.WriteLine(r);
}First of all, an instance of GraphViewConnection is required. In this case, graphConnection is the instance.
Then, an instance of GraphViewCommand is created, which needs a GraphViewConnection as a parameter.
In gremlin, g(), V(), Has("name") and Out("created") are called steps. In C#, they are method callings. It is obvious that the execution order of this method chaining is g(), V(), Has("name") and Out("created").
g() creates a GraphTraversal instance.
V() adds a GremlinVOp in a GremlinTranslationOpList included in the GraphTraversal instance.
Has("name") adds a GremlinHasOp to the same GraphTraversal.
Out("created") adds a GremlinOutOp to the same GraphTraversal.
Therefore, GraphView gets a traversal object with a GremlinTranslationOpList, which maintains information about all steps. That is, the traversal object contains all the information about this query.
When Next() of the traversal is called, GraphView gets an instance of WSqlScript through a series of complicated procedures. In fact, this instance is a SQL syntax tree which we will explain later. The result of WSqlScript_Instance.ToString() is like the following
SELECT ALL N_1.* AS value
FROM node AS [N_0], node AS [N_1]
MATCH N_0-[Edge AS E_0]->N_1
WHERE
EXISTS (
SELECT ALL R_0.value AS value
FROM CROSS APPLY Properties(N_0.name) AS [R_0]
) AND E_0.label = 'created'As you can see, there is some differences between this SQL-like script and the standard SQL query. But now we just ignore these differences for the moment.
Given a SQL-like query, which provides information in the same order as the Gremlin query's. However, this order may not be the optimal order.
We use AggregationBlock to spilt all tableReferences to several parts. In one AggregationBlock, we can change the order as long as they obey the input dependency. We spilt a query according to side-effect TVFs (aggregate, store, group, subgraph, tree), global filters (coin, dedup(global), range(global)), global maps (order(global), select), barriers (barrier), modification TVFs (addV, addE, commit, drop, property) and some special TVFs (constant, inject, sample(global)). The reason is the senmatics of these TVFs.
We use ExecutionOrder to transfer information to the compilation part. Every ExecutionOrder.Order is a list, recording 5 parts' information
- A
CompileNode(an abstract representation of a tableReference) is anMatchNode(corresponding to a free node) orNonFreeTable(correspongding to a TVF), called "currentNode", which is going to execute - A
CompileLink(an abstract representation of an edge or a predicate) is an link from previous state to current state. It can be aMatchEdge(correspongding to a free edge), or aPredicateLinkofWEdgeVertexBridgeExpression(linking a non-free edge with a free node), called "traversalLink" - A list of
PredicateLinkandint, called "forwardLinks", which contains all links between currentNode and previous state, and corresponding priority. - A list of
MatchEdgeandint, called "backwardEdges", which contains all edges that need to be retrieved, and corresponding priority. - A list of
ExecutionOrders, called "localExecutionOrders", which contains all execution orders in this TVFs or Derived tables.
As you can see, ExecutionOrder is another representation about the original Gremlin query. We can use these orders to compile and execute directly.
Then how to generate an optimal order? We use beam search to search most feasible solutions. If we have a perfect cost function to evaluate an order (12/15/2017), then the optimization ican improve the performance markedly.
After the optimization part finished, GraphView compiles this ExecutionOrder and gets a linked list of GraphViewExecutionOperator. Different tableReference compiles to different GraphViewExecutionOperator. Every GraphViewExecutionOperator records its input operator. That is to say, GraphView just needs the last operator in this list as it needs the head of one linked list.
For the GraphViewExecutionOperator list, it calls Next() until the result is not null. Then the execution of this Gremlin query is done.
Briefly spearking, GraphViewExecutionOperator are two types of execution. The one calls once inputOp.next() and returns once, the other calls multiple times inputOp.next() and puts them in a buffer, then returns elements in this buffer. We the latter one "in batch". It depends on the senmatics and efficient.
Now (8/1/2017) we are working on branch clean-up. Generally, we have two subprojects, GraphView and GraphViewUnitTest .
This is our core codes.
Include the C# API about Gremlin.
Gremlin is written in Java 8. There are various language variants of Gremlin such as Gremlin-Groovy, Gremlin-Python, Gremlin-Scala, Gremlin-JavaScript, Gremlin-Clojure, etc. It is best to think of Gremlin as a style of graph traversing that is not bound to a particular programming language per se.
And what we do in this file is implementing the Gremlin-API in C#.
GraphViewCommand command = new GraphViewCommand(graphConnection);
var traversal = command.g().V().Out("created").Has("name", "lop");
var result = traversal.Next();It provides the ability of communication between the GraphView and datebase (i.e. CosmosDB, MariaDB).
It's the main member of a GraphViewConnection object, which sends specific queries to database to execute. You can derive a new DBPortal to communicate another database if necessary.
The implementation of translation from almost all Gremlin steps to our defined SQL-like language script (maybe named GraphViewQuery?) .
--command.g().V().Has("name", "josh")
SELECT ALL N_0.* AS value
FROM node AS [N_0]
WHERE N_0.name = 'josh'The definition of SQL-like syntax tree. In fact, we store the translation result as a SQL-like syntax tree.
Compile the SQL-like syntax tree to an GraphViewExecutionOperator list.
Accept the result of GraphViewQueryCompiler (the operator list) and execute the operators via GraphViewConnection.
Just as its name.
Something about DocumentDB Identifier Normalization. Just ignore it.
It defines a GraphView query or command. It would have a VertexObjectCache for each instance.
When GraphView loads data from the database, it stores data in the VertexObjectCache via hash. If we update some VertexFields, we need update the related cache immediately. And if some data we need has been loaded before, we can get them in memory instead of the database to reduce the time.
Just as its name.
There are some unit tests.
There are two different graph data we can use directly, GraphData.MODERN and GraphDataCLASSIC. We can choose either through the LoadGraphData function.
This is a test file provided for any developer to run some queries and debug. Pay attention, this file doesn't need to be committed.
It defines an abstract class AbstractGremlinTest, which is used to identify classes that contain test methods and not abled to be inherited.
In fact, the translation part is the most amazing part in GraphView. A gremlin-groove query is a sequence of steps (Imperative programming). However, it is hard to optimize. We want to translate the query to a descriptive format (Declarative programming),that is the SQL-like format. A SQL query consists of SELECT, FROM, WHERE clauses, but the SQL-like format adds the MATCH clause, which is used to find the neighbors of vertices or the edges of vertices.
MATCH N_1-[Edge E_1]->N_2This clause can find the outgoing edge E_1 of vertices N_1, and the neighbors N_2 through E_1.
MATCH N_1<-[Edge E_1]-N_2This clause can find the incoming edge E_1 of vertices N_1, and the neighbors N_2 through E_1.
g.V("1") can get one vertex whose id is 1, g.V("1").out() can find the neighbors of g.V("1")...
We can use a finite-state machine to simulate this process.
Consider the Gremlin query g.V("1").out().outE(), the initial state is the whole graph, the vertex set N_1 = {v| v is a vertex whose label is "1"} is the next state, which is determined by g.V("1"). The next state is the vertex set N_2 = {v | There exists an edge from a vertex in N_1 to v}. The last state is the edge set E_1 = {The outgoing edges of any vertex in N_2}.
Pay attention, not all steps can be represented by states. For example, the FSM of g.V().hasLabel("person") has only one state, the vertex set N_1 = {v| v is a vertex who have the "person" label}.
How to build the FSM?
We do not build a FSM directly from the a Gremlin query due to some historical reasons. We build a GremlinTranslationOpList firstly. Generally, every step in gremlin can correspond to a GremlinTranslationOperator, such as V() and GremlinVOp, has("...") and GremlinHasOp. Every GremlinTranslationOperator can maintain the information of the corresponding step so that the GremlinTranslationOpList can maintain the information of the gremlin query. This GremlinTranslationOpList belongs to a traversal object. The GremlinTranslationOpList of g.V("1").out().outE() is [GrenlinVOp, GremlinOutOp, GremlinOutEOp]
Our model is a lazy model, that is to say we generate something only when we need it. If we want to get the last state of the FSM, we need the previous state, then previous... until the first state.
After we get a traversal object, we call the method Next(). This methodis very complex, but only two main processes are related to the translation, GetContext() and ToSqlScript(). GetContext() is the method to build the FSM.
Due to the lazy property, we just need to call GetContext() on the last GremlinTranslationOperator of the GremlinTranslationOpList. It calls GetContext() on the previous GremlinTranslationOperator... The first GremlinTranslationOperator is an object of GrenlinVOp. We will create an instance of GremlinFreeVertexVariable. Because we want the vertex whose id is "1" rather all vertices, we need to add a predicate in order to ensure {v| v is a vertex whose id is "1"}. We need to add the instance to a VariableList, which maintains all GremlinTranslationOperator, add the it to a TableReferencesInFromClause, which is used to generate the FROM clause, and set it as the PivotVariable, which means the current state in FSM, and add it to StepList, which maintains all states.
The first state is generated, then how to transfor it to the next state?
We maintain all information about FSM in an instance of GremlinToSqlContext. Because C# pass objects by reference, we can add new information on the previous object. Finally, we can use an object of GremlinToSqlContext to represent the FSM. Therefore, we can return an object of GremlinToSqlContext to the next state.
The next GremlinTranslationOperator is an object of GremlinOutOp. We need to get an object of GremlinFreeEdgeVariable and then an object of GremlinFreeVertexVariable. Then add the two to VariableList and TableReferencesInFromClause, but only set the latter as the PivotVariable and add it to StepList. Because the second state of the FSM is {v | There exists an edge from a vertex in N_1 to v}. If you still remember, MATCH can be used to find edges. Therefore, we add the object of GremlinFreeVertexVariable to MatchPathList.
GremlinOutEOp is the next and the last one. Similar to the GremlinTranslationOperator, add an object of GremlinVertexToForwardEdgeVariable to VariableList and MatchPathList and set the object as the PivotVariable and add it to StepList.
So far, the construction of FSM is finished.
During constructing the FSM, we created VariableList, TableReferencesInFromClause, Predicates, StepList and PivotVariable. We will use them to get the SQL-like query.
Because our ultimate goal is to get the final state so that the SELECT of SQL-like query is determined by the PivotVariable.
As we know, in some cases, not all the columns are needed. We just explicitly state the columns (or projectedProperties) we record. But if we do not record any columns, we will state the DefaultProjection. For example, the PivotVariable of g.V() is an object of GremlinFreeVertexVariable without any column given so that the SELECT will get the DefaultProjection * of GremlinFreeVertexVariable, like SELECT ALL N_1.* AS value. TheDefaultProjection is * if and only if the type of GremlinVariableType is Edge or Vertex, else the DefaultProjection is value. Now the PivotVariable of g.V("1").out().outE() is an object of GremlinFreeEdgeVariable without any column given so that the SELECT clause is SELECT ALL E_2.* AS value
This part is the most complicated. Keep in mind that GraphView is a lasy and pull system. Assume that TableReferencesInFromClause is
Therefore, if we traverse TableReferencesInFromClause from 1 to n, we do not know the properties the latter object of GremlinTableVariable needs. The wiser way is to traverse in the reverse order. If one object of GremlinTableVariable needs some properties, it will "tell" previous objects. g.V("1").out().outE() is so simple that it does not use this information.
Now, TableReferencesInFromClause is [GremlinFreeVertexVariable, GremlinFreeVertexVariable]. The first one is created due to g.V("1"), the second one is created due to .out(). We firstly call ToTableReference on the second GremlinFreeVertexVariable. The ToTableReference method is designed to translate GremlinTableVariable to WTableReference. GremlinFreeVertexVariable is so simple that the instance is just like node AS [N_2]. So similarly, the first instance is node AS [N_1]
Finally, we put them into a list, [node AS [N_1], node AS [N_2]]. And the FROM clause is FROM node AS [N_1], node AS [N_2]
Maybe you never hear the MATCH clause before, but it is easy to understand. The result of MatchClause is [N_1-[Edge AS E_1]->N_2, N_2-[Edge AS E_2]]. Every element is an object of WMatchPath with three parts, SourceVariable, EdgeVariable and SinkVariable. Take N_1-[Edge AS E_1]->N_2 for example, N_1 is the SourceVariable, E_1 is the EdgeVariable and N_2 is the SinkVariable. Repeat it again, the MATCH clause is MATCH N_1-[Edge AS E_1]->N_2 N_2-[Edge AS E_2]
Predicates is generated during building the FSM. But how to compose many predicates? Every predicate is an instance of WBooleanExpression, which has two instances of WBooleanExpression. You can image it as one node in a binary tree. If one predicate is added, just need to create an object of WBooleanExpression to store the new predicate, create an instance of WBooleanExpression to merge the old object and the new object with AND, OR. We can use the result to represent all predicates. Finally, the WHERE clause is WHERE N_1.id = '1'
SELECT ALL E_2.* AS value
FROM node AS [N_1], node AS [N_2]
MATCH N_1-[Edge AS E_1]->N_2
N_2-[Edge AS E_2]
WHERE N_1.id = '1'Then the translation part is finished. However, it is the simplest example. We will show you more.
It is obvious that a database is not good enough if it does not support modification. But it is still hard in traditional SQL databases to do some complex operations, such as branch. That's the reason why we introduce Table-Valued Functino from SQL Server.
A table-valued function is a user-defined function that returns a table.
Given a TVF(Table-Valued Function), we need pay attention to the main three parts:
- the scheme of input
- the scheme of output
- what it will do
In GraphView, that means a TVF if you see CROSS APPLY in the result of translation. Now (12/15/2017), GraphView supports free variables and TVFs survives together and their order can be changed before compilation if the senmatic keeps.
But the parameters in a TVF may not be the scheme of input.
For instance, the mearning of g().V().optional(__().out()).values("name") is
- if one vertex has neighbours, then return its neighbours' names
- else return its name
optional is a branch operator in fact, we could rewrite it via if-esle. However, traditional SQL databases can not support. When it comes to optional, we need to mention 3 parts.
- the scheme of input is one column that all vertices' information in the graph
- the scheme of output is one column that corresponds names
- the operator will try to return neighbours' names, otherwise, return the vertex's name.
The final SQL-like query is given as follows
SELECT ALL R_0.value AS value
FROM node AS [N_0],
CROSS APPLY
Optional(
(
SELECT ALL N_0.name AS name
UNION ALL
SELECT ALL N_1.name AS name
FROM CROSS APPLY VertexToForwardEdge(N_0.*, '*') AS [E_0], node AS[N_1]
WHERE E_0._sink = N_1.id
)
) AS [N_2], CROSS APPLY Values(N_2.name) AS [R_0]As you can see,CROSS APPLY Optional(...), CROSS APPLY VertexToForwardEdge(...),CROSS APPLY Values(...) are all TVFs.
Then explain the three TVFs:
-
CROSS APPLY VertexToForwardEdge(...)It is the first execution TVF because it a part of
Optionaland it is the first one inOptional. The input isN_0.*that is all vertices' information in the graph. The output isE_0that are edges connected withN_0and all edges in the graph. There are 2 parameters,N_0.*means the real input of this TVF and*points the scheme of output, one column named*.*means all information of vertices and edges, and here it means edges' information. And you can understand that the input of a TVF may not equal to the parameters of a TVF. -
CROSS APPLY Optional(...)This TVF is a branch operator in fact. The first part indicates the result if the second part returns empty. The second part indicates the expected result. The input of the TVF is
N_0.*, the output is one column that correspondesname. The reason why the result isnamerather than others is the senmatic ofg().V().optional(__().out()).values("name"). So you must know that the output ofoptionalis decided by followed steps. That is the main reason why GraphView is a pull system. The parameters ofOptionalconbines withUNION. The parameters andUNIONare defined before we design the system. And it is the constract between translation and compilation( with optimization). You can never tangle it. -
CROSS APPLY Values(...)This TVF is very simple. Get the values of one column and copy it as a new column. So you can useR_0.valueto accessN_2.name.
All in all, the input of a TVF does not equal to the parameters of a TVF. We need care more about the real input because the parameters are human-designed in order to satisfy some special demands.
Generally, it is common to use some queries to realize some functions. For example, if we want to add an edge in one graph, we need the sink vertex and source vertex. In GraphView, we need to use queries to find vertices. Therefore, we usually use subqueries in one complicated query。
A traverser is transformed as it moves through a series of steps within a traversal. The history of the traverser is realized by examining its path with path()-step (map).
- path can record all traces, even some traversers terminate early, their paths will also be listed.
- A faltMap-step will transform the incoming traverser’s object to an iterator of other objects. So the number of paths will turn several times.
- The traversers in the one path may be duplicates.
-- The SQL-like script translated from 'g().V().Out().Out().Path()'
SELECT ALL R_0.value AS value
FROM node AS [N_0], node AS [N_1], node AS [N_2],
CROSS APPLY
Path(
Compose1('value', N_0.*),
Compose1('value', N_1.*),
Compose1('value', N_2.*),
(
SELECT ALL Compose1(R_1.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'value') AS [R_1]
)
) AS [R_0]
MATCH N_0-[Edge AS E_0]->N_1
N_1-[Edge AS E_1]->N_2In CROSS APPLY Path(...), there are some Compose1 clauses and a subquery with Compose1 and Decompose1. Compose1 is aim to extract some columns and rename them(i.e. Compose1(N_0.*, 'value'), N_0.* will be the default projection and N_0.* will rename as value). Only these columns which have been populated will be extracted. However, not all these populated columns are needed in path. Therefore, Decompose1 will choose these columns which the path needs(i.e. Decompose1(C.value, 'value'), only value will be choosed). After Decompose1, we need to Compose1 the result of Decompose1 finally.
Because in CROSS APPLY Path(...), there is a subquery with CROSS APPLY Decompose1, it belongs to Subquery with TVF.
As you can see, TVFs are powerful tools to help SQL to execute complex queries. But if the subqueries are simple, we do not need TVFs.
The addV()-step is used to add vertices to the graph (map/sideEffect). For every incoming object, a vertex is created. Moreover, GraphTraversalSource maintains an addV() method.
- GraphView will add a vertex in the graph if there is no subgraph given.
- If there are some steps before add-step, this step will execute multiply times.
-- The SQL-like script translated from 'g().AddV("person")'
SELECT ALL N_0.* AS value
FROM
(
SELECT ALL '1'
) AS [_]
CROSS APPLY
AddV(
'person',
(list, '*', null)
) AS [N_0]This query is special because it has (SELECT ALL '1') AS [_]. In translation part, firstly we will build a GremlinTranlationOpList with an instance of GremlinAddVOp. Then it will build an object of GremlinToSqlContext with an instance of GremlinAddVVariable, in fact a FSM. When the instance of GremlinAddVVariable calls ToTableReference, the reference will set the first table reference as (SELECT ALL '1') AS [_] because the instance of GremlinAddVVariable is the first one in GremlinToSqlContext.VariableList and there is no subgraph or graph before. It is easy to understand that we must add a vertex in a graph which we must give explicitly. Therefore, we need the subquery, (SELECT ALL '1') AS [_]. Although we need the subquery, it does not contain a TVF. Therefore, it belongs to Subquery without TVF
When it is important that a traverser not repeat its path through the graph, simplePath()-step should be used (filter). The path information of the traverser is analyzed and if the path has repeated objects in it, the traverser is filtered.
- simplePath-step is just a filter. If we want all paths without repeat, we need use
simplePath().path()
-- The SQL-like script translated from 'g().V(1).Out().Out().SimplePath()'
SELECT ALL N_2.* AS value
FROM node AS [N_0], node AS [N_1], node AS [N_2],
CROSS APPLY
Path(
Compose1(N_0.*, 'value'),
Compose1(N_1.*, 'value'),
Compose1(N_2.*, 'value'),
(
SELECT ALL Compose1(R_1.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'value') AS [R_1]
)
) AS [R_0], CROSS APPLY SimplePath(R_0.value) AS [R_2]
MATCH N_0-[Edge AS E_0]->N_1
N_1-[Edge AS E_1]->N_2
WHERE N_0.id = 1Before we filter simplepath, we need get path first. However, the parameter of SimplePath is the default projection of the result of Path. Therefore, it belongs to Subquery without TVF.
The regex is
CROSS APPLY SimplePath(pathDefaultProjectionScalarExpression)Something about the translation part implementation of path-step in Gremlin
A traverser is transformed as it moves through a series of steps within a traversal. The history of the traverser is realized by examining its path with path()-step (map).
Let's see three translation results as below:
-- The SQL-like script translated from 'g.V().path()'
-- or 'g.V().path().by()'
-- or 'g.V().path().by(__.identity())'
SELECT ALL R_0.value AS value
FROM node AS [N_0],
CROSS APPLY
Path(
Compose1(N_0.*, 'value'),
(
SELECT ALL Compose1(R_1.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'value') AS [R_1]
)
) AS [R_0]-- The SQL-like script translated from 'g.V().out().path()' or ...
SELECT ALL R_0.value AS value
FROM node AS [N_0], node AS [N_1],
CROSS APPLY
Path(
Compose1(N_0.*, 'value'),
Compose1(N_1.*, 'value'),
(
SELECT ALL Compose1('value', R_1.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'value') AS [R_1]
)
) AS [R_0]
MATCH N_0-[Edge AS E_0]->N_1-- The SQL-like script translated from 'g.V().out().path().by("name")'
-- or 'g.V().out().path().by(__.values("name"))'
SELECT ALL R_0.value AS value
FROM node AS [N_0], node AS [N_1],
CROSS APPLY
Path(
Compose1(N_0.*, 'value', N_0.name, 'name'),
Compose1(N_1.*, 'value', N_1.name, 'name'),
(
SELECT ALL Compose1(R_2.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'name') AS [R_1], CROSS APPLY Values(R_1.name) AS [R_2]
)
) AS [R_0]
MATCH N_0-[Edge AS E_0]->N_1Here, V() creates a FreeVariable N_0 and out() creates a FreeVariable N_1. So in this traversal, each traverser will take along a path (history) including two elements, N_0 and N_1. And we can see that the TVF Path in script has n Compose1 and 1 subquery with Compose1 and Decompose1.
Each Compose1 corresponds one step. The Compose1 has many parameters. The first and second are DefaultProjectionScalarExpression, TableDefaultColumnName. The rest of parameters are another projectPropertyScalarExpression and projectProperty. One Compose1 will generate a CompositeField during runtime part.
After all Compose1 functions, there is a subquery finally in the majority situation. Each CompositeField contains all information about this step, but not all of it is useful. The first example only needs value, the second only needs value, the last only needs name. Therefore, the last subquery use Decompose1 and Compose1 to extract what we really need. We can use by(...) to point out the processes of all elements. The symbol C in Decompose1 is a bound variable of the input, pointing to each Compose1 in Path argument list.
-- g.V().as("a").out().path()
SELECT ALL R_0.value AS value
FROM node AS [N_0], node AS [N_1],
CROSS APPLY
Path(
Compose1(N_0.*, 'value'),
'a',
Compose1(N_1.*, 'value'),
(
SELECT ALL Compose1(R_1.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'value') AS [R_1]
)
) AS [R_0]
MATCH N_0-[Edge AS E_0]->N_1-- g.V().as("a").out().as("b").path()
SELECT ALL R_0.value AS value
FROM node AS [N_0], node AS [N_1],
CROSS APPLY
Path(
Compose1(N_0.*, 'value'),
'a',
Compose1(N_1.*, 'value'),
'b',
(
SELECT ALL Compose1(R_1.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'value') AS [R_1]
)
) AS [R_0]
MATCH N_0-[Edge AS E_0]->N_1-- g.V().as("a").as("b").out().as("c").path()
SELECT ALL R_0.value AS value
FROM node AS [N_0], node AS [N_1],
CROSS APPLY
Path(
Compose1(N_0.*, 'value'),
'a',
'b',
Compose1(N_1.*, 'value'),
'c',
(
SELECT ALL Compose1(R_1.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'value') AS [R_1]
)
) AS [R_0]
MATCH N_0-[Edge AS E_0]->N_1As you can see, the label will be a parameter after its related Variable in Path parameter list. And any step can have multiple labels.
CROSS APPLY Path (
(
Compose1(
DefaultProjectionScalarExpression, TableDefaultColumnName
(, projectPropertyScalarExpression, projectProperty)*
),
(StepLabelsAtThatMoment,)*
)
(
byContextSubQuery,
)
)Generally, we need the total path from the first step to the last step. But Gremlin provides sub-paths using from() and to() modulations with respective, path-based steps. This is useful in simplePath() and cyclicPath().
-- g.V().as('a').out('created').as('b').in('created').as('c').simplePath().from('a').to('b').path()
SELECT ALL R_0.value AS value
FROM node AS [N_0], node AS [N_1], node AS [N_2],
CROSS APPLY
Path(
Compose1(N_0.*, 'value'),
'a',
Compose1(N_1.*, 'value'),
'b'
) AS [R_0], CROSS APPLY SimplePath(R_0.value) AS [R_1]
MATCH N_0-[Edge AS E_0]->N_1
N_1<-[Edge AS E_1]-N_2
WHERE E_0.label = 'created' AND E_1.label = 'created'It is easy to get the sub-path as long as we can find these steps from the step with the label given by from to the step with the label given by to. If we have more than one step labeled by the same label, what should we do? Gremlin prefers the last step if there are some steps with the same label. That is to say, if the path is a->a->a->b->b->b->c->c->c, the sub-path from(a) and to(c) is a->b->b->b->c->c->c. So we need to walk backwards. If the query has no to() or we find the label given by to(), we begin to add steps into StepList until we find the label given by from().
-- g.V().union(__.inE().outV(), __.outE().inV()).both().path()
SELECT ALL R_2.value AS value
FROM node AS [N_0],
CROSS APPLY
Union(
(
SELECT ALL R_0.value AS _path, N_1.* AS *
FROM CROSS APPLY VertexToBackwardEdge(N_0.*, '*') AS [E_0], node AS [N_1], CROSS APPLY
Path(
Compose1(E_0.*, 'value'),
Compose1(N_1.*, 'value')
) AS [R_0]
WHERE E_0._source = N_1.id
),
(
SELECT ALL R_1.value AS _path, N_2.* AS *
FROM CROSS APPLY VertexToForwardEdge(N_0.*, '*') AS [E_1], node AS [N_2],
CROSS APPLY
Path(
Compose1(E_1.*, 'value'),
Compose1(N_2.*, 'value')
) AS [R_1]
WHERE E_1._sink = N2.id
)
) AS [N_3], CROSS APPLY VertexToBothEdge(N_3.*, '*') AS [E_2], CROSS APPLY EdgeToOtherVertex(E_2.*, 'value', '*') AS [N_4],
CROSS APPLY
Path(
Compose1(N_0.*, 'value'),
N_3._path,
Compose1(N_4.*, 'value'),
(
SELECT ALL Compose1(R_3.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'value') AS [R_3]
)
) AS [R_2]In this case, g.V().union(__.inE().outV(), __.outE().inV()).both().path(), if one traverser which has finished this traversal has walked through the path in order V -> inE -> outV -> both, the GraphView got V -> union -> both at first and N_3._path pointed to the path in sub traversal of union (called local path). Then N_3._path would be flattened and inserted into the global path. So after replacing the N_3._path with inE -> outV (for this traverser), we get the final path result V -> inE -> outV -> both.
Something about the implementation of select-step in Gremlin
-
Select labeled steps within a path (as defined by as() in a traversal).
-
Select objects out of a Map<String,Object> flow (i.e. a sub-map).
-
When the set of keys or values (i.e. columns) of a path or map are needed, use select(keys) and select(values), respectively.
-
When many steps have the same label (both name and type), the latter will be chosen.
-
When many steps have labels with the same name, the priority order from high to low is
Priority Type of Label High store,aggregateLow As
-- The SQL-like script translated from g.V().as("a").out().select("a").values("name", "age")
-- or g.V().as("a").out().select("a").by().values("name", "age")
-- or g.V().as("a").out().select("a").by(__.identity()).values("name", "age")
SELECT ALL R_3.value AS value
FROM node AS [N_0], node AS [N_1],
CROSS APPLY
Path(
Compose1(N_0.*, 'value', N_0.name, 'name', N_0.age, 'age'),
'a'
) AS [R_0],
CROSS APPLY
SelectOne(
N_1.*,
R_0.value,
'All',
'a',
(
SELECT ALL Compose1(R_1.value, 'value', R_1.name, 'name', R_1.age, 'age') AS value
FROM CROSS APPLY Decompose1(C.value, 'name', 'age') AS [R_1]
),
'name',
'age'
) AS [R_2], CROSS APPLY Values(R_2.name, R_2.age) AS [R_3]
MATCH N_0-[Edge AS E_0]->N_1When using select-step with only one label, we will get the SQL-like script which includes a TVF SelectOne.
First three arguments in SelectOne:
-
N_1.*: The previous step of select-step, that is, theouting.V().as("a").out().select("a"). If this step returns a dict(map), theSelectOnewill select the value in this dict with key "a" (in this case, theoutvariable would not return a dict obviously). For instance,g.V().valueMap().select("name"), in which thevalueMapyields a dict(map) representation of the properties of an element. And thenselectwill select the value with key "name". -
R_0.value: The path ofg.V().as("a").out()in this case, which contains all the steps the traverser goes through (some steps are labeled, such asVwith label "a"). Soselectwill select the stepV. -
'All': The option of the "pop" operation. It could be'All','First'and'Last'.There is also an option to supply a Pop operation to select() to manipulate List objects in the Traverser:
gremlin> g.V(1).as("a").repeat(out().as("a")).times(2).select(first, "a") ==>v1 ==>v1 gremlin> g.V(1).as("a").repeat(out().as("a")).times(2).select(last, "a") ==>v5 ==>v3 gremlin> g.V(1).as("a").repeat(out().as("a")).times(2).select(all, "a") ==>[v1,v4,v5] ==>[v1,v4,v3]
The argument as label in SelectOne:
-
'a':g.V().as("a").out().select("a")so ... but pay attention:If the selection is one step, no map is returned. When there is only one label selected, then a single object is returned.
The argument that a sub SQL-like select query in SelectOne:
(SELECT ... FROM ... WHERE ... ): The sub traversal inbyafterselect. It will do some projections for results of select-step.
The last two arguments in SelectOne:
'name'and'age': The populated columns' name of theSelectOneresult.
-- g.V().as("a").out().as("b").in().select("a", "b").by("name").by(__.valueMap())
SELECT ALL R_5.value AS value
FROM node AS [N_0], node AS [N_1], node AS [N_2],
CROSS APPLY
Path(
Compose1(N_0.*, 'value', N_0.name, 'name'),
'a',
Compose1(N_1.*, 'value', N_1.name, 'name'),
'b'
) AS [R_0],
CROSS APPLY
Select(
N_2.*,
R_0.value,
'All',
'a',
'b',
(
SELECT ALL Compose1(R_2.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'name') AS [R_1], CROSS APPLY Values(R_1.name) AS [R_2]
),
(
SELECT ALL Compose1(R_4.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'value') AS [R_3], CROSS APPLY ValueMap(R_3.value, -1) AS [R_4]
)
) AS [R_5]
MATCH N_0-[Edge AS E_0]->N_1
N_1<-[Edge AS E_1]-N_2The situation of Select argument list is almost same as the SelectOne. Note that the first sub query translated from by("name") will apply to the selected value with label "a", and the second one will apply to the selected value with "b", and so on.
CROSS APPLY Select (
inputVariableDefaultProjectionScalarExpression,
pathDefaultProjectionScalarExpression,
("ALL"|"First"|"Last"),
(SelectKeys, )+
(
byContextSubQuery,
)*
)We will insert a GremlinGlobalPathVariable before each select-step because the select-step depends on path.
Something about the implementation of cap-step in Gremlin
The
cap()-step (barrier) iterates the traversal up to itself and emits the sideEffect referenced by the provided key. If multiple keys are provided, then aMap<String,Object>of sideEffects is emitted.
cap-step is different with select-step. If one label is given, cap-step will emit the related sideEffect, while select-step will select the related step within a path or select objects out of a Map<String,Object> flow. That is to say, the result of select-step depends on the previous step.
For example, in g.V().aggregate("x").out().cap("x").Unfold().Values("name"), cap("x") will emit aggregate("x"), which actually V(). So cap("x") will get all vertices and the results of this query are all names of vertices
However, g.V().aggregate('x').out().select("x").unfold().Values("name"), select("x") will get the result of aggregate("x") within a path if one vertex has at least one neighbor. Because there are 6 vertices, any of which has at least one neighbor, the final results of select("x") are 6*6 vertices. The results of this query are repeated six times for each name.
When it comes to multiple labels, the difference is similar if the select is not to select objects out of a Map<String,Object> flow.
-- g.V().aggregate("x").out().cap("x").Unfold().Values("name")
SELECT ALL R_3.value AS value
FROM
(
SELECT ALL Cap(('value'), 'x') AS value
FROM node AS [N_0], CROSS APPLY Aggregate((SELECT ALL Compose1(N_0.*, 'value', N_0.name, 'name') AS value), 'x') AS [R_0], CROSS APPLY VertexToForwardEdge(N_0.*, '*') AS [E_0], node AS [N_1]
) AS [R_1], CROSS APPLY Unfold(R_1.value, 'name') AS [R_2], CROSS APPLY Values(R_2.name) AS [R_3]
WHERE E_0._sink = N_1.idBecause the result of cap-step is independent of the previous step, we can't use a TVF to implement this function. We choose to use a subquery and SELECT the result of cap-step.
GraphView is a pull system, when it sees Values("name"), it will notice that cap("x") should provide name property. And then, cap will call populate for every sideEffect variable in its subquery. Therefore, CROSS APPLY Aggregate((SELECT ALL Compose1('value', ..., N_0.name, 'name', ...) AS value), 'x') AS [R_0] needs compose with name property. Cap(('value'), 'x') will find the sideEffect with label "x", which is R_0.
-- g.V().aggregate("x").out().aggregate("y").cap("x", "y")
SELECT ALL R_2.value AS value
FROM
(
SELECT ALL Cap(('value'), 'x', ('value'), 'y') AS value
FROM node AS [N_0], CROSS APPLY Aggregate((SELECT ALL Compose1('value', N_0.*, 'value', N_0.*, '*') AS value), 'x') AS [R_0], CROSS APPLY VertexToForwardEdge(N_0.*, '*') AS [E_0], node AS [N_1], CROSS APPLY Aggregate((SELECT ALL Compose1('value', N_1.*, 'value', N_1.*, '*') AS value), 'y') AS [R_1]
) AS [R_2]
WHERE E_0._sink = N_1.idThe difference is that there are multiple groups of parameters in the SELECT clause of the subquery.
(
SELECT ALL Cap(((projectionScalarExpression),label)+) AS defaultProjection
FROM ...
)When GraphView constructs a instance of GremlinCapVariable in GremlinTranslationOpList, the instance will keep the sideEffectVariables in its subqueryContext. When later steps need properties from cap, it will call populate. For each of sideEffectVariables, it will call populate respectively.
Something about the implementation of repeat-step in Gremlin
The repeat()-step (branch) is used for looping over a traversal given some break predicate. Below are some examples of repeat()-step in action.
We assume that you have know these usage cases such as
times(1).repeat(...)repeat(...).until(...)until(...).repeat(...)until(...).repeat(...).emit(...)emit(...).until(...).repeat(...)- etc
There are 3 important things
- input for each time
- output for each time
- repeat condition
-- g.V().repeat(__.out()).times(2).path().by('name')
SELECT ALL R_1.value AS value
FROM node AS [N_0],
CROSS APPLY
Repeat(
(
SELECT ALL N_0.* AS name, N_0.name AS name, null AS _path
UNION ALL
SELECT ALL N_1.* AS name, N_1.name AS name, R_0.value AS _path
FROM CROSS APPLY VertexToForwardEdge(R.key_1, '*') AS [E_0], node As [N_1]
CROSS APPLY
Path(
R._path,
Compose1(N_1.*, 'value', N_1.name, 'name')
) AS [R_0]
WHERE E_0._sink = N_1.id
),
RepeatCondition(2)
) AS [N_2],
CROSS APPLY
Path(
Compose1('value', N_0.*, 'value', N_0.name, 'name', N_0.*, '*'),
N_2._path,
(
SELECT ALL Compose1('value', R_3.value, 'value') AS value
FROM CROSS APPLY Decompose1(C.value, 'name') AS [R_2], CROSS APPLY Values(R_2.name) AS [R_3]
)
) AS [R_1]The out-step will execute 2 times. Because of .path().by("name"), the repeat-step provides name property and path.
For the first time, __.out() needs vertices from the step before repeat, that is V(). Then it can get the neighbors as the result. In addition, it also get the name property and path.
For the second time, __.out() needs vertices from last result(g.V().out()). Then it can get the neighbors as the result as well as name property and path.
...
(
SELECT ALL N_0.name AS key_0, N_0.* AS key_1, null AS _path
UNION ALL
SELECT ALL N_1.name AS key_0, N_1.* AS key_1, R_0.value AS _path
FROM CROSS APPLY VertexToForwardEdge(R.key_1, '*') AS [E_0], node AS [N_1],
CROSS APPLY
Path(
R._path,
Compose1('value', N_1.*, 'value', N_1.name, 'name', N_1.*, '*')
) AS [R_0]
WHERE E_0._sink = N_1.id
)
...The first SELECT clause would be run only one time to select the specific columns in RawRecord for align when the traverser comes in this repeat step at the first time. And null As _path is only the dummy padding.
The second time and later, the repeat-step receives the result of previous repeat as the input, applies the second SELECT clause. Here, R refers to previous output and R._path means the local path in previous repeat.
The most important thing is that the first SELECT clause and the second SELECT clause have the same scheme. The reason is obvious, no matter how many times we execute the repeat-step, the scheme should be the same. The first SELECT clause is related to the first time, and the second SELECT clause is related to the second time and later.
The scheme of repeat is determined by
- What projections do we need from the step before repeat-step(Here, we need
*). - What projections do we need to compute the until-condition(Here, none)
- What projections do we need to emit(Here, none)
- What projections do we need after the repeat-step(Here, we need
_pathandname).
A number of repeat rounds from argument of times, or an predicate or an EXISTS clause translated from sub traversal in until.
-- g.V().repeat(__.out()).times(2).path().by('name')
RepeatCondition(2)
-- g.V(1).repeat(out()).until(hasLabel('software')).path().by('name')
RepeatCondition(R.key_2 = 'software')
-- g.V(1).repeat(out()).until(has("lang")).path().by('name')
RepeatCondition(
EXISTS (
SELECT ALL R_0.value AS value
FROM CROSS APPLY Properties(R.key_2) AS [R_0]
))CROSS APPLY Repeat(
(
firstQueryExpr
UNION ALL
repeatQueryExpr
),
RepeatCondition
)There are four main steps in this algorithm
-
Generate the repeatQueryBlock in order that we can get the initial query, whose input is the step before repeat-step
-
Generate a inputVariableVistorMap, which maps the columns about the input of repeat-step to the columns which we name. This inputVariableVistorMap is generated via repeatVariable.ProjectedProperties, repeatInputVariable.ProjectedProperties, untilInputVariable.ProjectedProperties and emitInputVariable.ProjectedProperties. Generally, these properties are related to the input every time, but in the repeatQueryBlock, these are just related to the input of the first time. Therefore, we need to replace these after.
-
Generate the firstQueryExpr and the selectColumnExpr of repeatQueryBlock. Pay attention, we need to repeatQueryBlock again because we need more properties about the output of the last step in repeat-step. These properties are populated in the second step.
-
Use the inputVariableVistorMap to replace the columns in the repeatQueryBlock. But we should not change the columns in path-step. Because if we generate the path in the repeat-step, the path consists of
- the previous steps before the repeat-step
- the local path(_path) in the repeat-step
Keep in mind that the initial _path is null, the _path includes all steps as long as they are in the repeat-step except for the first input. And the _path after the first pass includes the last step in the repeat-step. So the path must include the two part. That means all columns in path-step should not be replaced. Here, we use the ModifyRepeatInputVariablesVisitor to finish this work. If it visits WPathTableReference, it does nothing, otherwise, it will replace the columns according to the inputVariableVistorMap.
Something about the implementation of match-step in Gremlin
The match-step in Gremlin is a map step, which maps the traverser to some object for the next step to process. That is, one traverser in, some object out. And match-step does the same thing as it.
With match(), the user provides a collection of "traversal fragments," called patterns, that have variables defined that must hold true throughout the duration of the match().
In official implementation of Gremlin, we found that when a traverser is in match(), a registered MatchAlgorithm (i.e. CountMatchAlgorithm or GreedyMatchAlgorithm) analyzes the current state of the traverser, the runtime statistics of the traversal patterns, and returns a traversal-pattern that the traverser should try next.
"Who created a project named 'lop' that was also created by someone who is 29 years old? Return the two creators."
In Gremlin, we can do as below:
// the gremlin query
g.V().match(
__.as('a').out('created').as('b'), // 1
__.as('b').has('name', 'lop'), // 2
__.as('b').in('created').as('c'), // 3
__.as('c').has('age', 29)). // 4
select('a','c').by('name')That means for each traverser processed in this match step will try to traverse all of the match-traversals, and if it completes four traversals (order-independent), it is matched.
We consider the modern graph in gremlin:
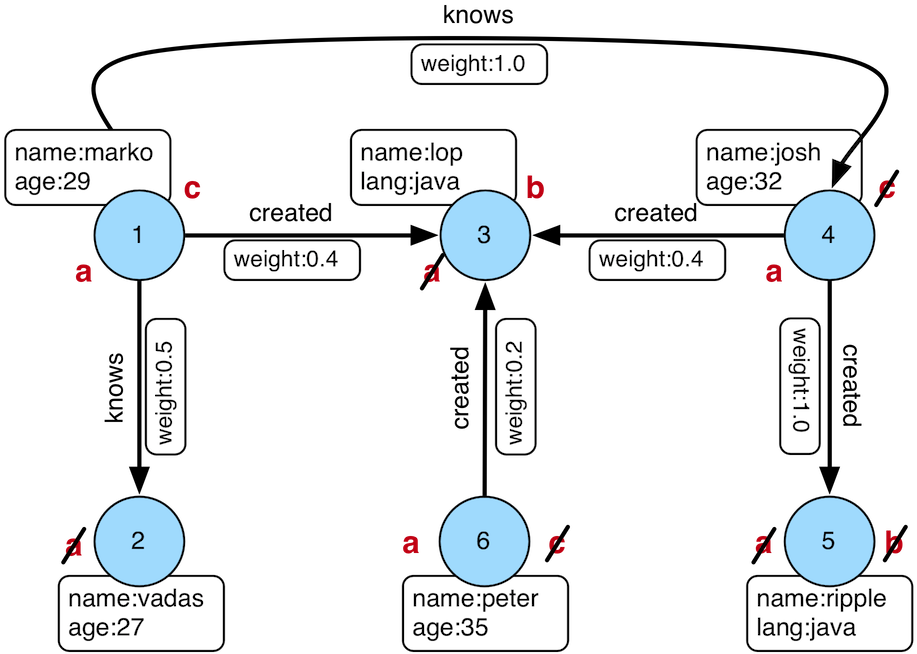
Now a traverser which current traversed vertex 1 comes in this match-step. If it is matched, a groovy-dict will be return, then select-step will takes the values' names by keys 'a' and 'c'.
We know that it may fails to finish all traversals in some orders. For example, we process this traverser in order 4-3-2-1. We consider vertex 1 (which this traverser current traversed) is 'c' because there is no label 'c' in this traverser's path, and it did have a property 'age' valued 29, so it success to pass through the match-traversal 4. And then in next traversal(match-traversal 3), we cannot find what is the 'b' pointing to, so it fails, or is not matched.
So in order to make it success to complete all traversals (if it can), we must choose a right order for it.
And some rules we should follow:
- The start/end label in
__.as('a').out('created').as('b')is 'a'/'b'; while__.as('c').has('age', 29)has no end label. - The first traversal it comes to, we will tag the traverser by the start label if the start label is not in its path.
- For each end label (if it exists), we will tag it on its path when it is processed by this traversal.
- For each start label in traversal, if we can not recognize it (the label not in the traverser's path), it fails.
- The result of match-step is a map(dict) including all the keys on all match-traversals (which are on the traverser's path without doubt).
First of all, we should find the proper order.
a -> b // 1
b -> null // 2
b -> c // 3
c -> null // 4
We can get a graph:
a -> b -> c
Well it is obvious that 1-2-3-4 is a right order, 1-3-4-2 as well. Ok, you may consider it just is a Partially ordered set, and I did a Topological sorting. But if it is not a DAG(directed acyclic graph), how should I do?
a -> b
b -> c
c -> a
a -> d
e -> f
We could ignore the x -> null (the match-traversal that just has start label) because we can put it behind of x -> y (the match-traversal that has start label and end label), which is a valid "edge".
so we will get the graph
+---------------+
| |
v +
a +---> b +---> c
+
|
v
d
If we start at 'a', we can go to 'b' and 'd' at the same time. Because the traverser can "split" another one to do the next traversal. So in this graph, starting at 'a', 'b', 'c' are the right ways, could complete all traversals.
For this, we say a > b, b > c, c > a, a > d, it is not satisfied to the partially order.
And of cause, Topological sorting can not be applied.
If there is a graph as below:
+---------------+
| |
v +
a +---> b +---> c
e +-----------> f
Obviously, if it is not a connectivity, let A = {a, b, c}, B = {e, f}, where anyone on the front does not matter.
For this graph:
g +------> e +--------> f
+ ^
| |
| |
| |
v +
h +------> a +--------> b <--+
^ + |
| | |
| | |
+ | |
d <----------+ |
+ |
| |
| |
+----------> c +--+
sorted result: []
Our solution is:
- Step 1: For every vertex, do the Breadth-first search (BFS) to find shortest paths between it and other vertices, and find the longest one in these shortest paths, mark this vertex with the length of this longest path:
5 +------> 1 +--------> 0
+ ^
| |
| |
| |
v +
4 +------> 3 +--------> 4 <--+
^ + |
| | |
| | |
+ | |
3 <----------+ |
+ |
| |
| |
+----------> 5 +--+
sorted result: []
- Step 2: Compare their results got from step 1, find the max one as the "global longest path" (if not only one, choose one arbitrarily):
g e +--------> f
^
|
|
|
+
h a b <--+
^ + |
| | |
| | |
+ | |
d <----------+ |
|
|
|
c +--+
sorted result: []
- Step 3: Move it out from the graph, add it to the result list, remove all the related edges:
g
+
|
|
|
v
h
sorted result: [ c, b, d, a, e, f ]
- Step 4: Loop the step 1, 2, 3 for the rest graph. Because of
g -> e, which means {g, h} > {c, b, d, a, e, f}, so we should put {g, h} on the front of the part {c, b, d, a, e, f}
sorted result: [ g, h, c, b, d, a, e, f ]
In Our GraphView Code, we polyfill the Match by FlatMap, Choose, Where, Select and so on, which means it is none of the compilation or execution parts' business, but only translation part.
g.V().match(
__.as('a').out('created').as('b'),
__.as('b').has('name', 'lop'),
__.as('b').in('created').as('c'),
__.as('c').has('age', 29),
)
// is equal to
g.V().flatMap(__.choose(__.select('a'), __.identity(), __.as('a')).
select(last, 'a').flatMap(__.out('created')).choose(__.select('b'), __.where(eq('b'))).as('b').
select(last, 'b').flatMap(__.has('name', 'lop')).
select(last, 'b').flatMap(__.in('created')).choose(__.select('c'), __.where(eq('c'))).as('c').
select(last, 'c').flatMap(__.has('age', 29)).
select('a', 'b', 'c'))We will string the match-traversals into one flatmap-traversal. (and will add some steps in it)
- There is no step corresponding to
FilterTVF in Gremlin. FilterTVF is aim to solve some problems related with steps(sideEffecttype orfiltertype).- Now(8/28/2017), the
FilterTVF is very simple but useful. It contains a CASE (Transact-SQL) , which provide the condition of this filter.
Consider a Gremlin query, g.V().aggregate("x").has("lang").cap("x"). The aggregate-step is used to aggregate all the vertices in this query. But in previous versions, we translate this Gremlin query to a SQL-like query as follows:
-- g.V().aggregate("x").has("lang").cap("x")
SELECT ALL R_2.value AS value
FROM
(
SELECT ALL Cap(('value'), 'x') AS value
FROM node AS [N_0], CROSS APPLY Aggregate((SELECT ALL Compose1(N_0.*, 'value') AS value), 'x') AS [R_1]
WHERE
EXISTS (
SELECT ALL R_0.value AS value
FROM CROSS APPLY Properties(N_0.lang) AS [R_0]
)
) AS [R_2]In fact, if we translate g.V().has("lang").aggregate("x").cap("x"), we can get this
-- g.V().has("lang").aggregate("x").cap("x")
SELECT ALL R_2.value AS value
FROM
(
SELECT ALL Cap(('value'), 'x') AS value
FROM node AS [N_0], CROSS APPLY Aggregate((SELECT ALL Compose1(N_0.*, 'value') AS value), 'x') AS [R_1]
WHERE
EXISTS (
SELECT ALL R_0.value AS value
FROM CROSS APPLY Properties(N_0.lang) AS [R_0]
)
) AS [R_2]The two SQL-like queries are same while the Gremlin query are different. The translation is wrong because latter one's aggregate-step only aggregates those who has "lang" property.
The deeper explanation is that we change the order of sideEffect-steps and filter-steps.
To simplify things, we consider only two steps: s and f, where s is a step of sideEffect type and f is a step of filter type.
s(xxx).f(yyy)means filter the result of sideEffect. All input ofswill yield some computational sideEffect.f(xxx).s(yyy)means yield some computational sideEffect on the result of filter. Only those that satisfy some conditions will be affected.
Above all, we need some tragedies to solve our mistake.
In GraphView, the priority of predicates in WHERE clause is higher that TVF in FROM clause. Therefore, GraphVIew must ensure that f is after s in s(xxx).f(yyy). So we design the filter TVF for f to take the place of predicates in WHERE clause.
Now, the translation result is
-- g.V().aggregate("x").has("lang").cap("x")
SELECT ALL R_3.value AS value
FROM
(
SELECT ALL Cap(('value'), 'x') AS value
FROM node AS [N_0], CROSS APPLY Aggregate((SELECT ALL Compose1(N_0.*, 'value') AS value), 'x') AS [R_0],
CROSS APPLY
Filter(
( CASE
WHEN
EXISTS (
SELECT ALL R_1.value AS value
FROM CROSS APPLY Properties(N_0.lang) AS [R_1]
) THEN 1
ELSE 0
END )
) AS [R_2]
) AS [R_3]It is easy to understand if you know the CASE (Transact-SQL). If exists one element which has "lang" property, the Filter will get 1, else get 0.
Because Aggregate is before Filter in WHERE clause, the Filter won't have a influence on Aggregate.
CROSS APPLY Filter(
( CASE
WHEN
Predicate THEN 1
ELSE 0
END )
)Not all filters should be translated to a filter TVF because of poor efficiency. Only when the input of filter has been affected by one sideEffect-step or more sideEffect-steps. In Gremlin, coin, cyclicPath, dedup, drop, range, simplePath, timeLimit, limit, and, or, not, is, has, where are of sideEffect type. and, or, not, is, has, where use predicates to implement. So we may need Filter TVF to make sure our translation result is correct in face of them as well as sideEffect steps.
In translation part, we use a local variable NeedFilter to keep information about sideEffect. If current state of FSM is affected by a sideEffect-step, GraphView will assign true to it. During translation, if we face a filter-step, such as and, or, not, is, has and where, we must use Filter TVF to make sure the correct order if NeedFilter is true. NeedFilter is a member variable of GramlinVariable, so if the current state(pivotVariable) is changed, the NeedFilter will be initialed as false.
GraphView is under the MIT license.