![]()
slStreamUtils is a set of tools that try to improve the (de)serialization performance over an I/O stream. Amongst other improvements over the standard FileStream class, it also offers multithreaded stream (de)serialization support for both protobuf-net and MessagePack-CSharp. For MessagePack, it introduces framing over the stream without breaking compatibility with the underlying protocol (allowing to exchange files between different languages and OS), but might require some adaptation of your class definitions. For Protobuf, which already has native message framing support, no modifications are needed. Please read the post for the underlying implementation details.
- .NET Standard 2.0, 2.1 and newer
- The base package, slStreamUtils
, contains the Stream extensions
- The package slStreamUtilsProtobuf
, extending Protobuf-net for framed multi-threaded stream serialization
- The package slStreamUtilsMessagePack
, extending MessagePack-CSharp for framed multi-threaded stream serialization



{kind=link}
{kind=link}
{kind=link}
Bencharks are available through the projects under Benchmarks/slStreamUtilsBenchmark
Two data sets are used:
- Large Objects – a collection of 4096 objects, each taking ~16KB, for a combined size of ~67MB
- Small Objects – a collection of 123K objects, each taking 550B, for a combined size of aprox. 66MB
This benchmark measures the read and write speed of a collection of objects of the same type T and of unknown length (as for example iterating an IEnumerable) to/from a MemoryStream.

It compares the native implementations using Protobuf-net
foreach (var obj in arr)
ProtoBuf.Serializer.SerializeWithLengthPrefix(stream, obj, ProtoBuf.PrefixStyle.Base128, 1);
X obj;
while ((obj = ProtoBuf.Serializer.DeserializeWithLengthPrefix<X>(stream, ProtoBuf.PrefixStyle.Base128, 1)) != null)
yield return obj;vs parallel implementation in slStreamUtils using an increasingly larger # of threads
await using var ser = new CollectionSerializerAsync<X>(stream, new FIFOWorkerConfig(maxConcurrentTasks: 2));
foreach (var item in arr)
await ser.SerializeAsync(item);
using var ds = new CollectionDeserializerAsync<X>(new FIFOWorkerConfig(maxConcurrentTasks: 2));
await foreach (var item in ds.DeserializeAsync(stream))
yield return item.Item;This benchmark measures the read and write speed of a collection of objects of the same type T and of unknown length (as for example iterating an IEnumerable) to/from a MemoryStream.
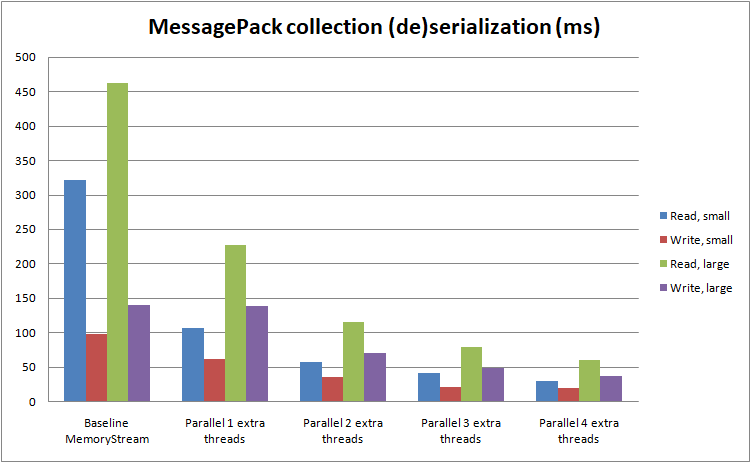
It compares the native implementations using MessagePack-CSharp
using var stream = File.Create(fileName);
foreach (var obj in arr)
await MessagePackSerializer.SerializeAsync<Frame<X>>(stream, obj);
using var sr = new MessagePackStreamReader(stream);
while (await sr.ReadAsync(CancellationToken.None) is ReadOnlySequence<byte> msgpack)
yield return MessagePackSerializer.Deserialize<Frame<X>>(msgpack);vs parallel implementation in slStreamUtils using an increasingly larger # of threads
await using var ser = new CollectionSerializerAsync<X>(stream, maxConcurrentTasks: 2);
foreach (var item in arr)
await ser.SerializeAsync(item);
using var ds = new CollectionDeserializerAsync<X>(maxConcurrentTasks: 2);
await foreach (var item in ds.DeserializeAsync(stream))
yield return item;Note: It's natural to see MessagePack's original implementation being significantly slower because we’re using MessagePack.MessagePackStreamReader to read from a stream of undetermined length. This method will scan ahead and parse the stream until it finds the end of the current element, returning that segment of bytes, and only then will we deserialize it using MessagePackSerializer.Deserialize, ultimately resulting in having to do the same work twice, which is inevitable since we don't have any framing information telling us where the current message block ends. If we were deserializing buffers of a known size, we’d only have to call MessagePackSerializer.Deserialize, which would be much faster, as can be seen in the next benchmark.
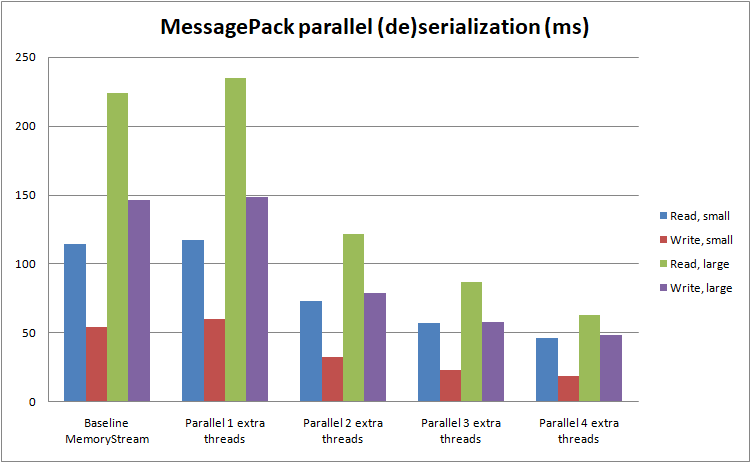
This benchmark measures the read and write speed of an object containing fields of type Frame[] to/from a MemoryStream.
Original type:
[MessagePackObject]
public class SomeClass
{
// some fields
[Key(0)]
public AnotherClass[] arr;
// some more fields
}New, frame-enabled type:
[MessagePackObject]
public class SomeClass
{
// some fields
[Key(0)]
public Frame<AnotherClass>[] arr; // this will be (de)serialized in parallel since it's wrapped in *Frame<>*
// some more fields
}Notice how we've wrapped AnotherClass with the struct Frame, which is little else besides an int field and a ref to AnotherClass:
[MessagePackObject]
public struct Frame<T>
{
[Key(0)]
public int BufferLength { get; internal set; }
[Key(1)]
public T Item { get; set; }
}To (de)serialize an instance of SomeClass using MessagePack-CSharp's original implementation, one would write
await MessagePackSerializer.SerializeAsync(stream, obj, opts);
var newObj = await MessagePackSerializer.DeserializeAsync<ArrayX>(stream, opts);And to make the above code run in parallel, just add the new Frame resolver to your options
var opts = new FrameParallelOptions(totWorkerThreads,
MessagePackSerializerOptions.Standard.WithResolver(FrameResolverPlusStandarResolver.Instance));Besides the examples in the Examples and Benchmark folder, I recomend to read my blog which contains more in-depth information about the techniques used, particularly for the stream framing.