

DotnetSpider, a .NET Standard web crawling library. It is lightweight, efficient and fast high-level web crawling & scraping framework
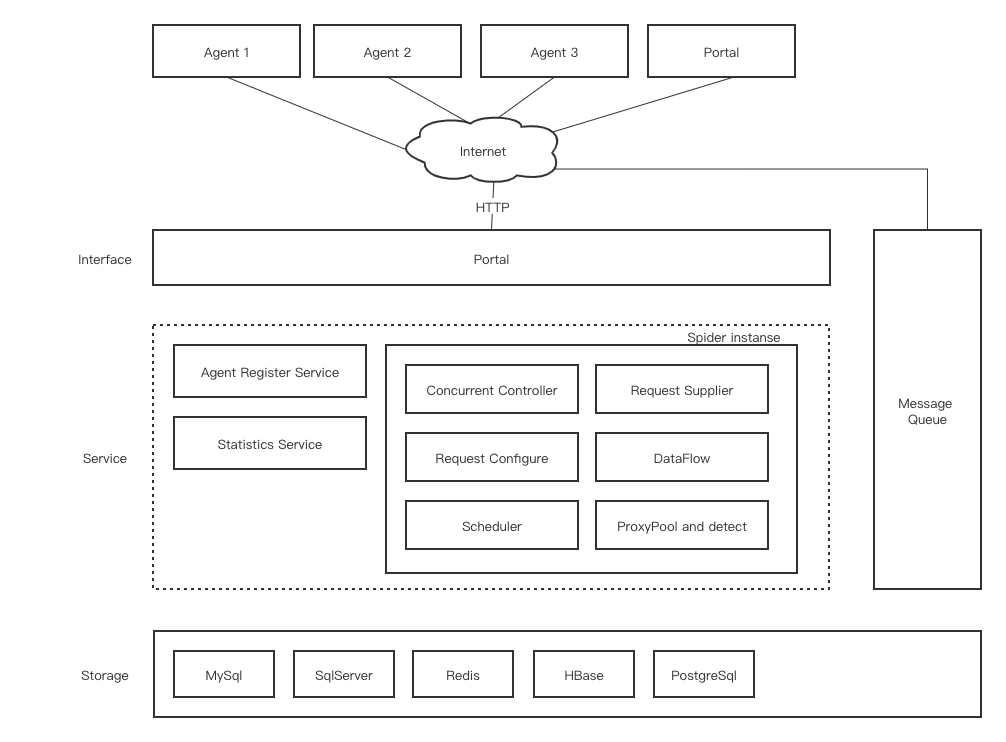
-
Visual Studio 2017 (15.3 or later) or Jetbrains Rider
-
Docker
-
MySql
docker run --name mysql -d -p 3306:3306 --restart always -e MYSQL_ROOT_PASSWORD=1qazZAQ! mysql:5.7 -
Redis (option)
docker run --name redis -d -p 6379:6379 --restart always redis -
SqlServer
docker run --name sqlserver -d -p 1433:1433 --restart always -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=1qazZAQ!' mcr.microsoft.com/mssql/server:2017-latest -
PostgreSQL (option)
docker run --name postgres -d -p 5432:5432 --restart always -e POSTGRES_PASSWORD=1qazZAQ! postgres -
MongoDb (option)
docker run --name mongo -d -p 27017:27017 --restart always mongo -
Kafka
docker run -d --restart always --name kafka-dev -p 2181:2181 -p 3030:3030 -p 8081-8083:8081-8083 \ -p 9581-9585:9581-9585 -p 9092:9092 -e ADV_HOST=192.168.1.157 \ landoop/fast-data-dev:latest -
Docker remote api for mac
docker run -d --restart always --name socat -v /var/run/docker.sock:/var/run/docker.sock -p 2376:2375 bobrik/socat TCP4-LISTEN:2375,fork,reuseaddr UNIX-CONNECT:/var/run/docker.sock -
Docker registry
docker run -d --restart always --name registry -p 5000:5000 --name registry registry:2 -
Add hosts
{your id} registry.zousong.com {your id} kafka.zousong.com {your id} zousong.com
https://github.com/dotnetcore/DotnetSpider/wiki
Please see the Project DotnetSpider.Sample in the solution.
public class EntitySpider : Spider
{
public static void Run()
{
var builder = new SpiderBuilder();
builder.AddSerilog();
builder.ConfigureAppConfiguration();
builder.UseStandalone();
builder.AddSpider<EntitySpider>();
var provider = builder.Build();
provider.Create<EntitySpider>().RunAsync();
}
protected override void Initialize()
{
NewGuidId();
Scheduler = new QueueDistinctBfsScheduler();
Speed = 1;
Depth = 3;
DownloaderSettings.Type = DownloaderType.HttpClient;
AddDataFlow(new DataParser<BaiduSearchEntry>()).AddDataFlow(GetDefaultStorage());
AddRequests(
new Request("https://news.cnblogs.com/n/page/1/", new Dictionary<string, string> {{"网站", "博客园"}}),
new Request("https://news.cnblogs.com/n/page/2/", new Dictionary<string, string> {{"网站", "博客园"}}));
}
[Schema("cnblogs", "cnblogs_entity_model")]
[EntitySelector(Expression = ".//div[@class='news_block']", Type = SelectorType.XPath)]
[ValueSelector(Expression = ".//a[@class='current']", Name = "类别", Type = SelectorType.XPath)]
class BaiduSearchEntry : EntityBase<BaiduSearchEntry>
{
protected override void Configure()
{
HasIndex(x => x.Title);
HasIndex(x => new {x.WebSite, x.Guid}, true);
}
public int Id { get; set; }
[Required]
[StringLength(200)]
[ValueSelector(Expression = "类别", Type = SelectorType.Enviroment)]
public string Category { get; set; }
[Required]
[StringLength(200)]
[ValueSelector(Expression = "网站", Type = SelectorType.Enviroment)]
public string WebSite { get; set; }
[StringLength(200)]
[ValueSelector(Expression = "//title")]
[ReplaceFormatter(NewValue = "", OldValue = " - 博客园")]
public string Title { get; set; }
[StringLength(40)]
[ValueSelector(Expression = "GUID", Type = SelectorType.Enviroment)]
public string Guid { get; set; }
[ValueSelector(Expression = ".//h2[@class='news_entry']/a")]
public string News { get; set; }
[ValueSelector(Expression = ".//h2[@class='news_entry']/a/@href")]
public string Url { get; set; }
[ValueSelector(Expression = ".//div[@class='entry_summary']", ValueOption = ValueOption.InnerText)]
public string PlainText { get; set; }
[ValueSelector(Expression = "DATETIME", Type = SelectorType.Enviroment)]
public DateTime CreationTime { get; set; }
}
public EntitySpider(IMessageQueue mq, IStatisticsService statisticsService, ISpiderOptions options, ILogger<Spider> logger, IServiceProvider services) : base(mq, statisticsService, options, logger, services)
{
}
}
$ cd src/DotnetSpider.DownloaderAgent
$ sh build.sh
$ mkdir -p /Users/lewis/dotnetspider/logs/agent
$ docker run --name agent001 -d --restart always -e "DOTNET_SPIDER_AGENTID=agent001" -e "DOTNET_SPIDER_AGENTNAME=agent001" -e "DOTNET_SPIDER_KAFKACONSUMERGROUP=Agent" -v /Users/lewis/dotnetspider/agent/logs:/logs registry.zousong.com:5000/dotnetspider/downloader-agent:latest
$ docker run --name agent002 -d --restart always -e "DOTNET_SPIDER_AGENTID=agent002" -e "DOTNET_SPIDER_AGENTNAME=agent002" -e "DOTNET_SPIDER_KAFKACONSUMERGROUP=Agent" -v /Users/lewis/dotnetspider/agent/logs:/logs registry.zousong.com:5000/dotnetspider/downloader-agent:latest
$ mkdir -p /Users/lewis/dotnetspider/portal & cd /Users/lewis/dotnetspider/portal
$ curl https://raw.githubusercontent.com/dotnetcore/DotnetSpider/master/src/DotnetSpider.Portal/appsettings.json -O
$ docker run --name dotnetspider.portal -d --restart always -p 7897:7896 -v /Users/lewis/dotnetspider/portal/appsettings.json:/portal/appsettings.json -v /Users/lewis/dotnetspider/portal/logs:/logs registry.zousong.com:5000/dotnetspider/portal:latest
When you want to collect a page JS loaded, there is only one thing to do, set the downloader to WebDriverDownloader.
Downloader = new WebDriverDownloader(Browser.Chrome);
NOTE:
- Make sure the ChromeDriver.exe is in bin folder when use Chrome, install it to your project from NUGET: Chromium.ChromeDriver
- Make sure you already add a *.webdriver Firefox profile when use Firefox: https://support.mozilla.org/en-US/kb/profile-manager-create-and-remove-firefox-profiles
- Make sure the PhantomJS.exe is in bin folder when use PhantomJS, install it to your project from NUGET: PhantomJS
timeout 0
tcp-keepalive 60

QQ Group: 477731655 Email: zlzforever@163.com