{kind=link}
Web based crawler for site broken links based on https://github.com/hmol/LinkCrawler Besides the crawl, this displays also the words with the highest frequency on the site
The technology is Microsoft ASP.NET Core 3 with SignalR for communication between browser and local webserver
This is a web based crawler that searches from broken links on a domain specified by the user from the browser. The result is written to both the client browser as well as to other outputs (e.g. csv)
Make sure you have Microsoft dotnet core 3 installed (currently in preview) on either Mac, Windows or Linux
Then run
git clone https://github.com/firecodergithub/ASPDotNetCoreCrawl
cd ASPDotNetCoreCrawl
dotnet run
Then simply connect your browser to http://localhost:5000 (it might redirect to https on port 5001 and complain about self signed certificate)
These are located in the file crawlSettings.json
| Key | Usage |
|---|---|
SuccessHttpStatusCodes |
HTTP status codes that are considered "successful". Example: "1xx,2xx,302,303" |
CheckImages |
If true, <img src=".." will be checked |
ValidUrlRegex |
Regex to match valid urls |
OnlyReportBrokenLinksToOutput |
If true, only broken links will be reported to output. |
Csv.FilePath |
File path for the CSV file |
Csv.Overwrite |
Whether to overwrite or append (if file exists) |
Csv.Delimiter |
Delimiter between columns in the CSV file (like ',' or ';') |
PrintSummary |
If true, a summary will be printed when all links have been checked. |
TimeMsBetweenRequests |
How long in miliseconds the app should wait until the next request to the crawled site |
TopWordsCount |
How many top words count should be displayed; default 20 |
RemoveStopWords |
Whether to ignore stop words from the top words (default = true) |
languageStopWords |
List of site extensions along with the name of the stopwords file |
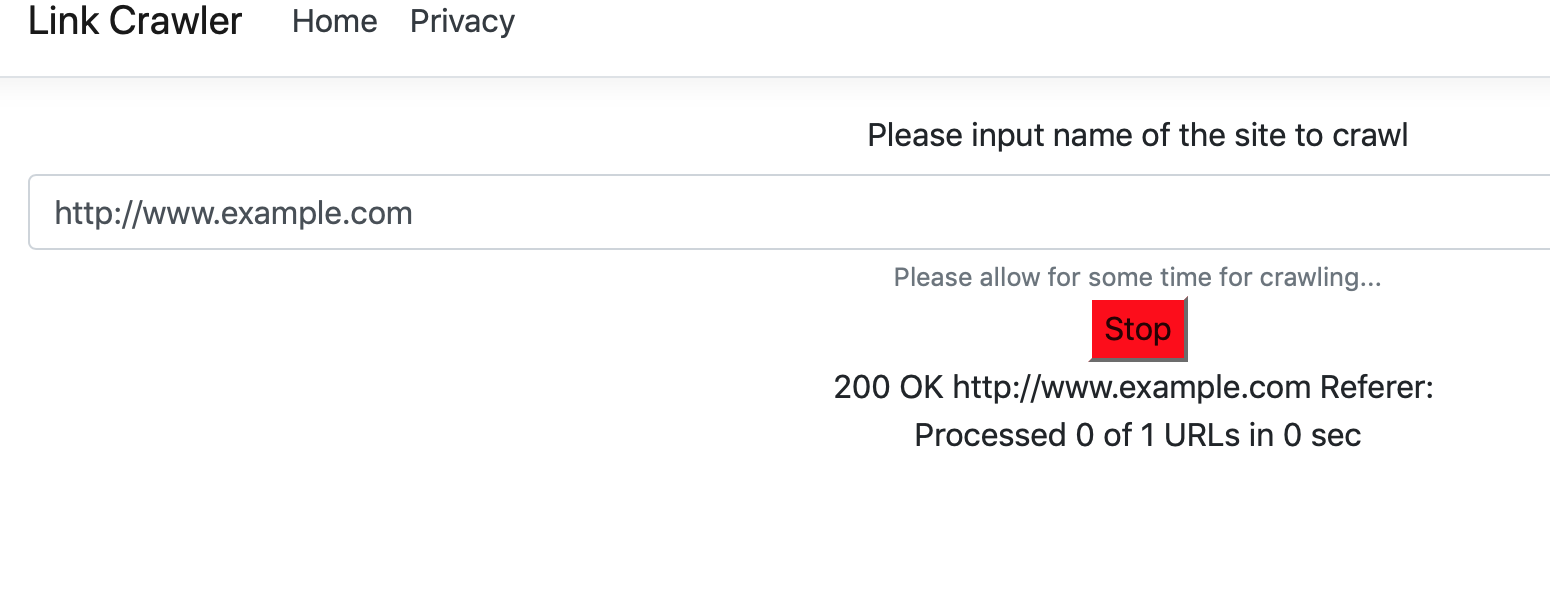
Once the browser connects to the local webserver, the root URL should be input (full URL, including http(s)) then click enter or press crawl
A live list of crawled links is displayed and the ones broken are appended to a table in the browser (and also saved on the csv output file on the webserver location)
The webserver used by dotnet is Kestrel. If you require setting it up on IIS or IIS Express look for the configuration steps on this on the web
The app is also deployable via docker to heroku through the dockerfile Sample free deployment is at: (might be offline due to free heroku site policy) https://crawlwords.herokuapp.com