This is a very old repository containg code written about 5 years ago. I've recently decided to take most of the repositories I have under private source control and publish to Github public repositories as a way of "releasing" them.
Because of the age of the project a lot of the descriptions bellow might not be quite acurate or full, especially the sections discussing current state and features.
! Prereq:
https://docs.microsoft.com/en-us/aspnet/mvc/mvc3
Build: Passed
Running Web: Easy enough - Just need a local instance of SQL Server and running Update-Database from Package Manager Console once all connection strings have been properly setup! The Migrations will run seeds as well.
Note: One part I could not get running was the Lucene index which I suspect requires some additional setup and local installations
The idea of the project came about after some discussions with some friends about building a system that would index grad papers.
We thought that it would be cool that grad papers from different faculties could be made easily searchable and a valuable resource for people starting university.
Unfortunatley the effort ended with those initial discussions, but I found it intriguing enough to do some research on how it can be done.
The project was started a while back and was based on the Lucene Library. To Get Lucene to work I relied on TIKA to extract text from different types of documents: Word/PDF/Excel.
The contents where then processed and analyzed using Lucene Analyzers and at some point stored in the Lucene Index.
The portal would then allow users to search based on different search parameters.
While working on this I remember also spending a lot of time on learning/implementing/working on monitoring and profiling features using EFProfiler, MiniProfiler, Elmah and similar.
The portal is build using Knockout and the Revealing Module Pattern. It uses Bootsrap 3 for the presentation and various UI libraries for different components like Toaster messages and Grids.
The database and initial seeding of data is done using Entity Framework Code and EF Migrations.
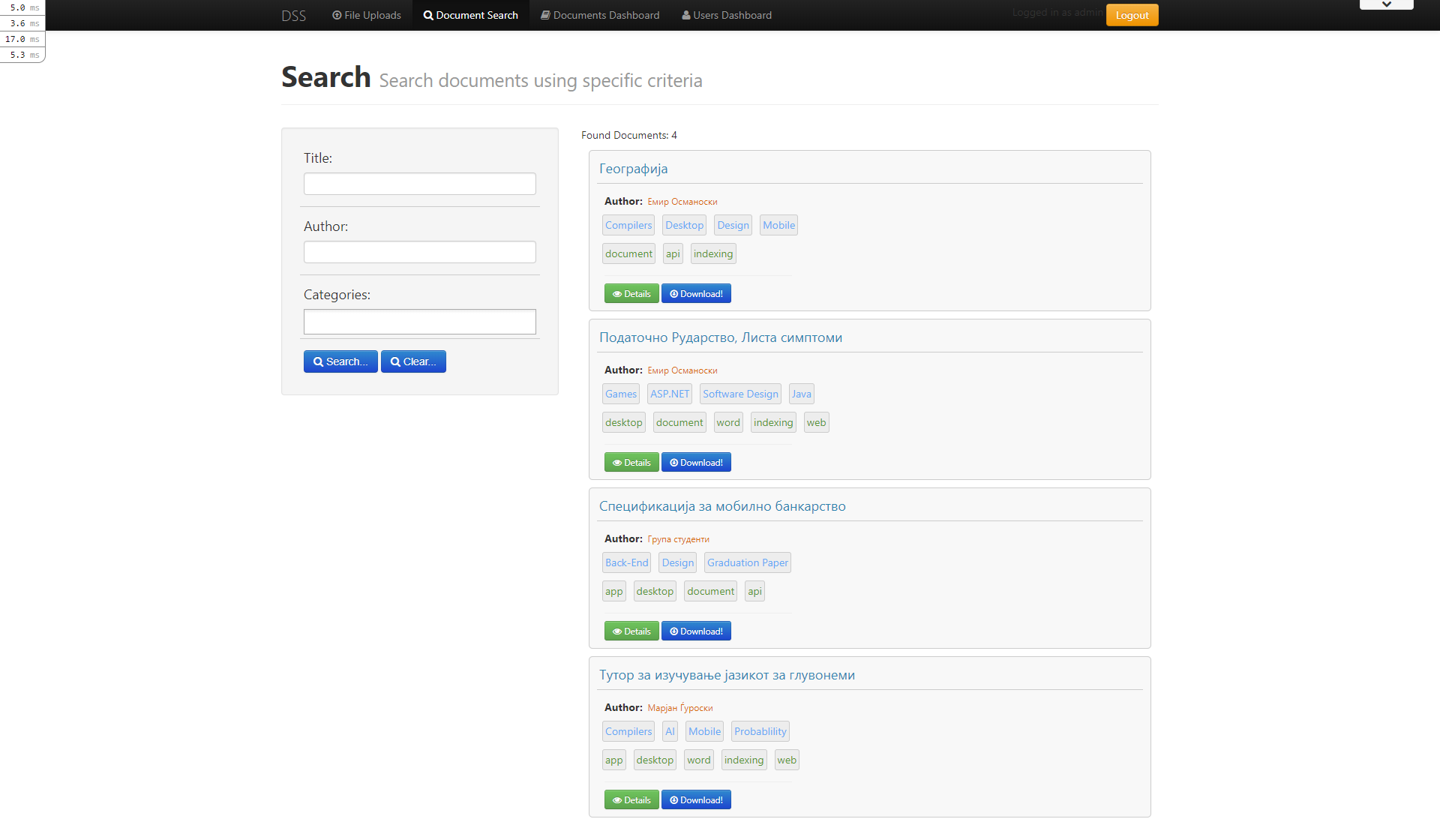
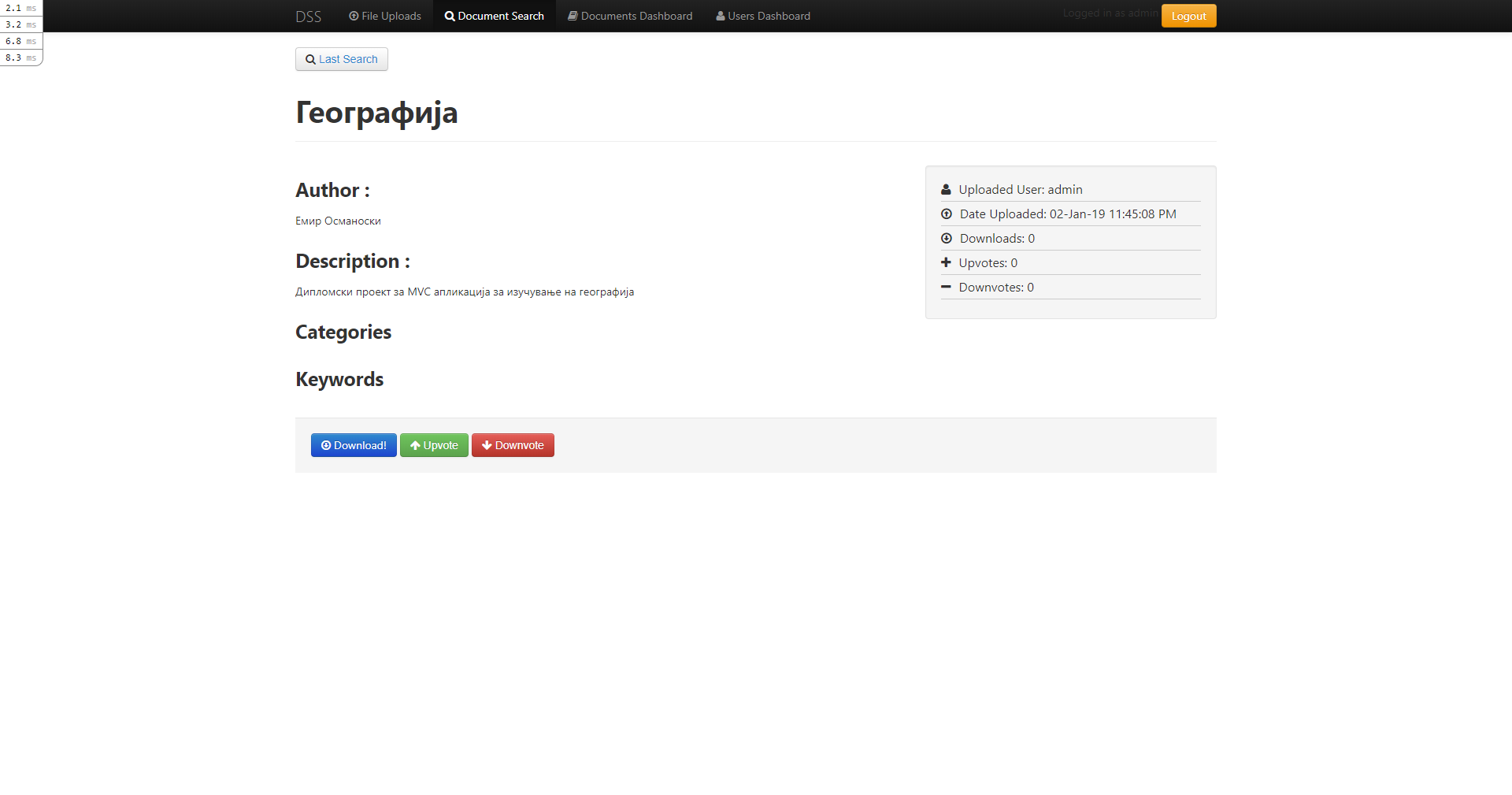
Last I remember I was working on showing/improving search results. The portal can be used to upload document and search based on keywords found in those documents.
The search worked based on content, keywords and categories.
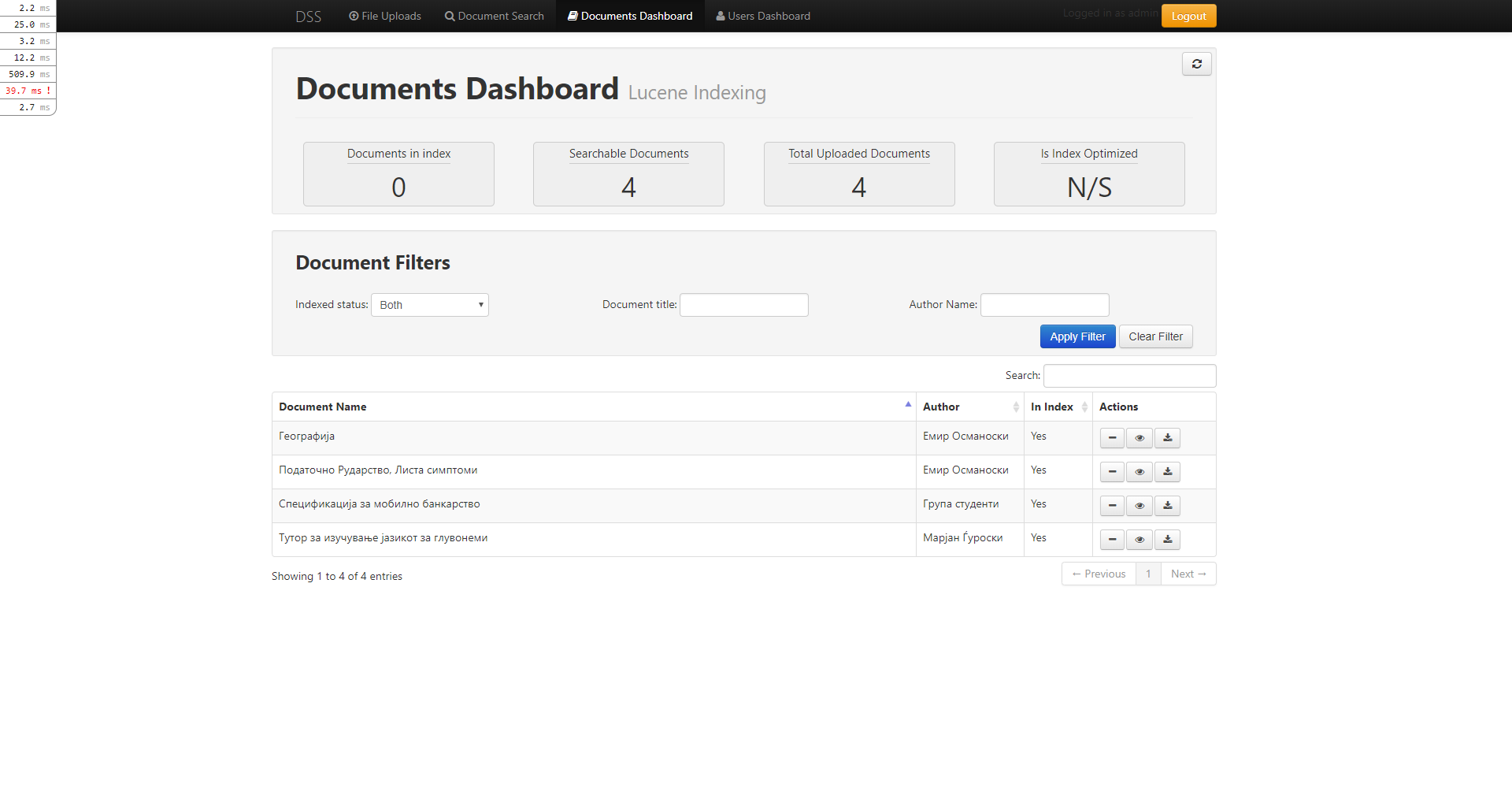
The Portal also contained a dashboard showing the index status, the number of uploaded documents and the number of indexed/searchable documents.
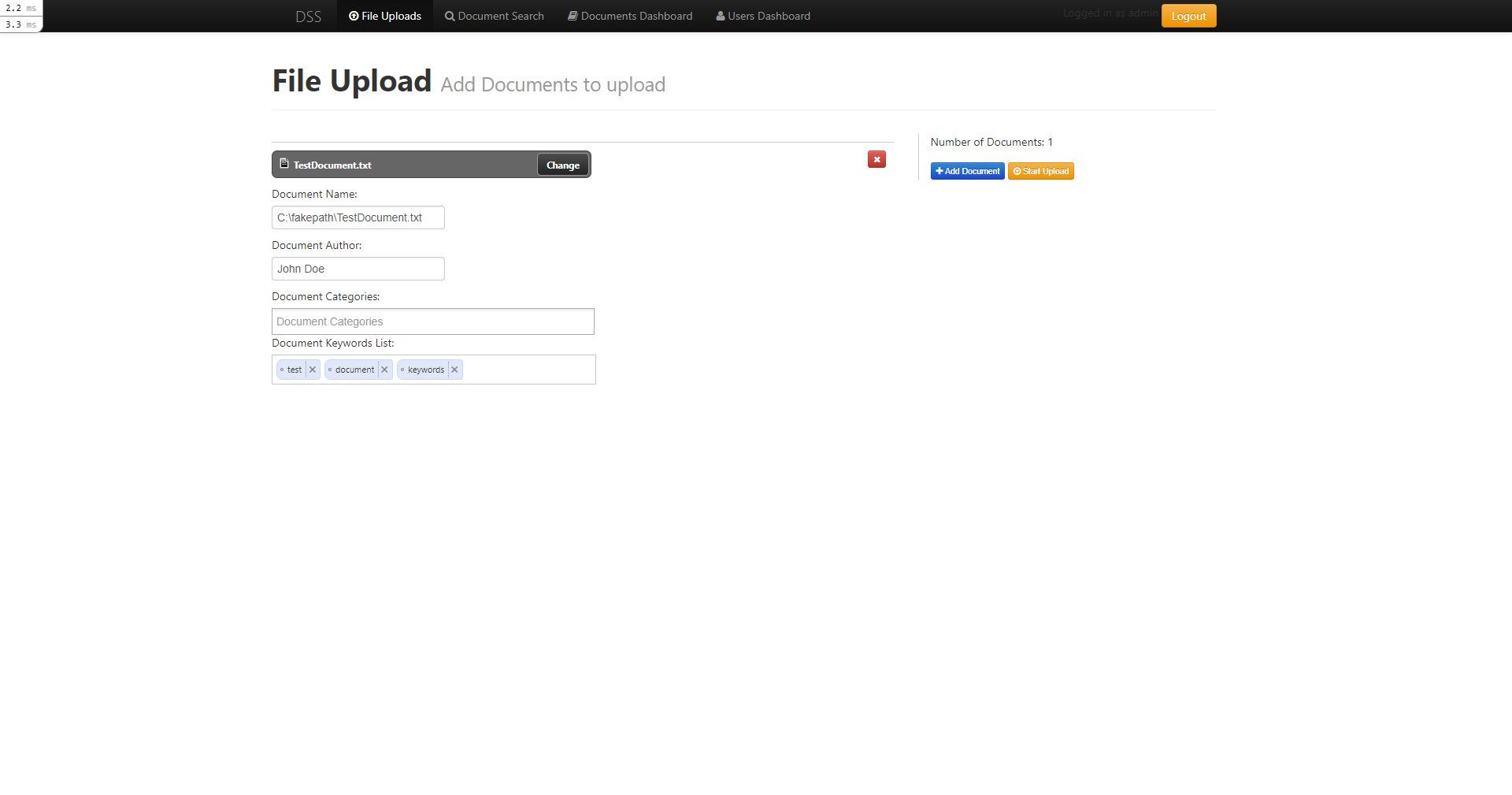
The Portal contained certain adiministrative features that could have been used to upload documents and control which documents were added or removed from the Lucene index.
Not much to say here. Used this project to start exploring more interesting things around organizing code and integrating thrid party solutions and libraries into exisint solution architectures.
Setting up Lucene was a PITA - considering that the text extraction tooling also required some work-arounds as at the time IIRC was not very advanced. Hence TIKA and Apache messing about.