The GridGain Community Edition (GCE) is a source-available in-memory computing platform built on Apache Ignite. GCE includes the Apache Ignite code base plus improvements and additional functionality developed by GridGain Systems to enhance the performance and reliability of Apache Ignite. GCE is a hardened, high-performance version of Apache Ignite for mission-critical in-memory computing applications.
For information on how to get started with GridGain CE, please visit: Getting Started.
GridGain, built on top of Apache Ignite, is a memory-centric distributed database, caching, and processing platform for transactional, analytical, and streaming workloads delivering in-memory speeds at petabyte scale.
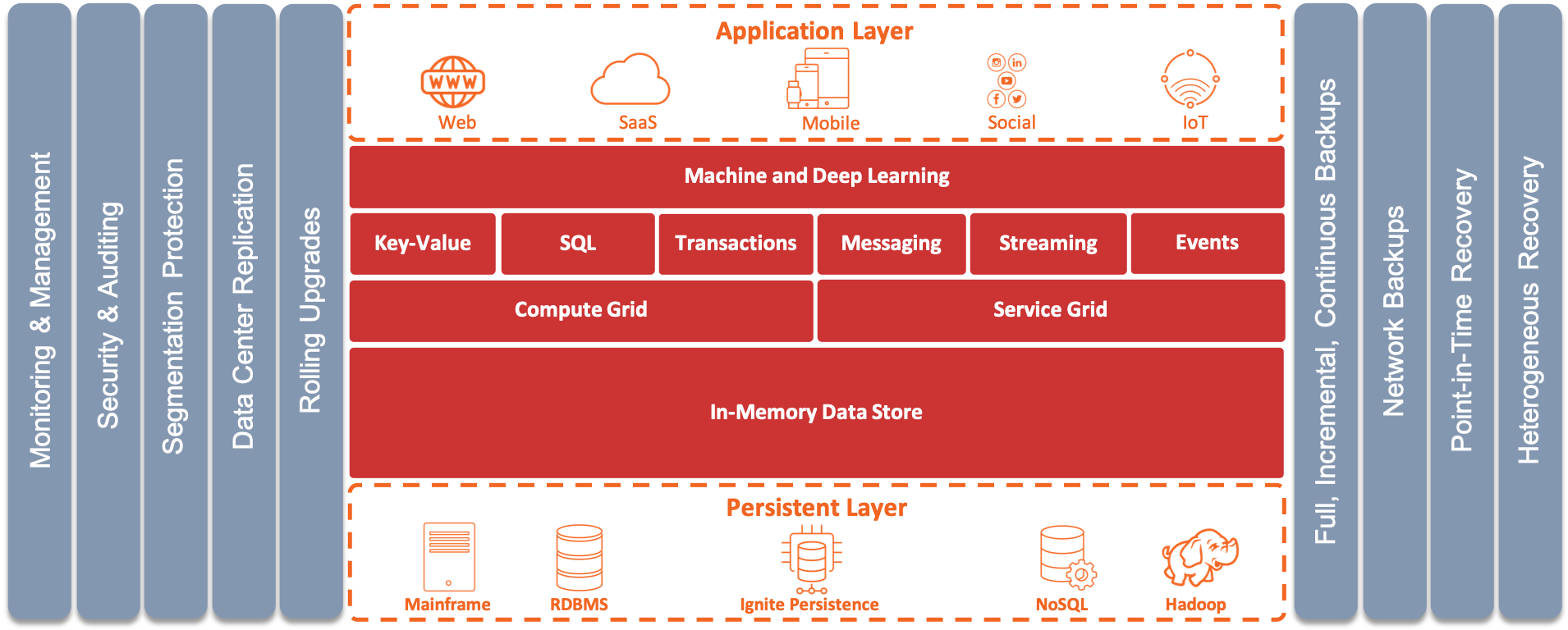
GridGain is based on distributed memory-centric architecture that combines the performance and scale of in-memory computing together with the disk durability and strong consistency in one system.
The main difference between the memory-centric approach and the traditional disk-centric approach is that the memory is treated as a fully functional storage, not just as a caching layer, like most databases do. For example, GridGain can function in a pure in-memory mode, in which case it can be treated as an In-Memory Database (IMDB) and In-Memory Data Grid (IMDG) in one.
On the other hand, when persistence is turned on, GidGain begins to function as a memory-centric system where most of the processing happens in memory, but the data and indexes get persisted to disk. The main difference here from the traditional disk-centric RDBMS or NoSQL system is that GridGain is strongly consistent, horizontally scalable, and supports both SQL and key-value processing APIs.
Native Persistence is a distributed, ACID, and SQL-compliant disk store that transparently integrates with GridGain memory-centric storage as an optional disk layer storing data and indexes on SSD, Flash, 3D XPoint, and other types of non-volatile storages.
With the Native Persistence enabled, you no longer need to keep all the data and indexes in memory or warm it up after a node or cluster restart because the Durable Memory is tightly coupled with persistence and treats it as a secondary memory tier. This implies that if a subset of data or an index is missing in RAM, the Durable Memory will take it from the disk.

Data stored in GridGain is ACID-compliant both in memory and on disk, making GridGain a strongly consistent system. GridGain transactions work across the network and can span multiple servers.
GridGain provides full support for SQL, DDL and DML, allowing users to interact with the cluster using pure SQL without writing any code. This means that users can create tables and indexes as well as insert, update, and query data using only SQL. Having such complete SQL support makes GridGain a one-of-a-kind distributed SQL database.
The in-memory data grid component in GridGain is a fully transactional distributed key-value store that can scale horizontally across 100s of servers in the cluster. When persistence is enabled, GridGain can also store more data than fits in memory and survive full cluster restarts.
Most traditional databases work in a client-server fashion, meaning that data must be brought to the client side for processing. This approach requires lots of data movement from servers to clients and generally does not scale. GridGain, on the other hand, allows for sending light-weight computations to the data, i.e. collocating computations with data. As a result, GridGain scales better and minimizes data movement.
GridGain is an elastic, horizontally scalable distributed system that supports adding and removing cluster nodes on demand. GridGain also allows for storing multiple copies of the data, making it resilient to partial cluster failures. If the persistence is enabled, then data stored in GridGain will also survive full cluster failures. Cluster restarts in GridGain can be very fast, as the data becomes operational instantaneously directly from disk. As a result, the data does not need to be preloaded in-memory to begin processing, and GridGain caches will lazily warm up resuming the in memory performance.
You can view Apache GridGain as a collection of independent, well-integrated components geared to improve performance and scalability of your application.
Some of these components include:
- Advanced Clustering
- Data Grid
- SQL Database
- Compute Grid
- Service Grid
- Spark Shared RDDs and SQL indexes
Below you’ll find a brief explanation for each of them.
GridGain nodes can automatically discover each other. This helps to scale the cluster when needed, without having to restart the whole cluster. Developers can also leverage from GridGain’s hybrid cloud support that allows establishing connection between private cloud and public clouds such as Amazon Web Services, providing them with best of both worlds.

GridGain can be deployed on:
GridGain data grid is an in-memory distributed key-value store which can be viewed as a distributed partitioned hash map, with every cluster node owning a portion of the overall data. This way the more cluster nodes we add, the more data we can cache.
Unlike other key-value stores, GridGain determines data locality using a pluggable hashing algorithm. Every client can determine which node a key belongs to by plugging it into a hashing function, without a need for any special mapping servers or name nodes.
GridGain data grid supports local, replicated, and partitioned data sets and allows to freely cross query between these data sets using standard SQL syntax. GridGain supports standard SQL for querying in-memory data including support for distributed SQL joins.

GridGain incorporates distributed SQL database capabilities as a part of its platform. The database is horizontally scalable, fault tolerant and SQL ANSI-99 compliant. It supports all SQL, DDL, and DML commands including SELECT, UPDATE, INSERT, MERGE, and DELETE queries. It also provides support for a subset of DDL commands relevant for distributed databases.
With GridGain Durable Memory architecture, data as well as indexes can be stored both in memory and, optionally, on disk. This allows executing distributed SQL operations across different memory layers achieving in-memory performance with the durability of disk.
You can interact with GridGain using the SQL language via natively developed APIs for Java, .NET and C++, or via the GridGain JDBC or ODBC drivers. This provides a true cross-platform connectivity from languages such as PHP, Ruby and more.

Distributed computations are performed in parallel fashion to gain high performance, low latency, and linear scalability. GridGain compute grid provides a set of simple APIs that allow users distribute computations and data processing across multiple computers in the cluster. Distributed parallel processing is based on the ability to take any computation and execute it on any set of cluster nodes and return the results back.

We support these features, amongst others:
- Distributed Closure Execution
- MapReduce & ForkJoin Processing
- Continuous Mapping
- Clustered Executor Service
- Per-Node Shared State
- Collocation of Compute and Data
- Load Balancing
- Fault Tolerance
- Job State Checkpointing
- Job Scheduling
Service Grid allows for deployments of arbitrary user-defined services on the cluster. You can implement and deploy any service, such as custom counters, ID generators, hierarchical maps, etc.
GridGain allows you to control how many instances of your service should be deployed on each cluster node and will automatically ensure proper deployment and fault tolerance of all the services.

GridGain supports complex data structures in a distributed fashion:
- Queues and sets: ordinary, bounded, collocated, non-collocated
- Atomic types:
AtomicLongandAtomicReference - CountDownLatch
- ID Generators
- Semaphore
Distributed messaging allows for topic based cluster-wide communication between all nodes. Messages with a specified message topic can be distributed to all or sub-group of nodes that have subscribed to that topic.
GridGain messaging is based on publish-subscribe paradigm where publishers and subscribers are connected together by a common topic. When one of the nodes sends a message A for topic T, it is published on all nodes that have subscribed to T.
Distributed events allow applications to receive notifications when a variety of events occur in the distributed grid environment. You can automatically get notified for task executions, read, write or query operations occurring on local or remote nodes within the cluster.
An alternate high-performant implementation of job tracker which replaces standard Hadoop MapReduce. Use it to boost your Hadoop MapReduce job execution performance.

GridGain provides an implementation of Spark RDD abstraction which allows to easily share state in memory across Spark jobs.
The main difference between native Spark RDD and GridGainRDD is that GridGain RDD provides a shared in-memory view on data across different Spark jobs, workers, or applications, while native Spark RDD cannot be seen by other Spark jobs or applications.

Both. Native persistence in GridGain can be turned on and off. This allows GridGain to store data sets bigger than can fit in the available memory. Essentially, the smaller operational data sets can be stored in-memory only, and larger data sets that do not fit in memory can be stored on disk, using memory as a caching layer for better performance.
Yes. Data in GridGain is either partitioned or replicated across a cluster of multiple nodes. This provides scalability and adds resilience to the system. GridGain automatically controls how data is partitioned, however, users can plug in their own distribution (affinity) functions and collocate various pieces of data together for efficiency.
Not fully. Although GridGain aims to behave like any other relational SQL database, there are differences in how GridGain handles constraints and indexes. GridGain supports primary and secondary indexes, however, the uniqueness can only be enforced for the primary indexes. GridGain also does not support foreign key constraints.
Essentially, GridGain purposely does not support any constraints that would entail a cluster broadcast message for each update and significantly hurt performance and scalability of the system.
Yes. Even though GridGain durable memory works well in-memory and on-disk, the disk persistence can be disabled and GridGain can act as a pure in-memory database.
Not fully. ACID Transactions are supported, but only at key-value API level. GridGain also supports cross-partition transactions, which means that transactions can span keys residing in different partitions on different servers.
At SQL level GridGain supports atomic, but not yet transactional consistency. GridGain community plans to implement SQL transactions in version 2.2.
Yes. GridGain provides a feature rich key-value API, that is JCache (JSR-107) compliant and supports Java, C++, and .NET.
Yes. GridGain is a full-featured data grid, which can be used either in pure in-memory mode or with native persistence. It can also integrate with any 3rd party database, including any RDBMS or NoSQL store.
GridGain durable memory architecture allows GridGain to extend in-memory computing to disk. It is based on a paged-based off-heap memory allocator which becomes durable by persisting to the write-ahead-log (WAL) and, then, to main GridGain persistent storage. When persistence is disabled, durable memory acts like a pure in-memory storage.
GridGain is a distributed system and, therefore, it is important to be able to collocate data with data and compute with data to avoid distributed data noise. Data collocation becomes especially important when performing distributed SQL joins. GridGain also supports sending user logic (functions, lambdas, etc.) directly to the nodes where the data resides and computing on the data locally.